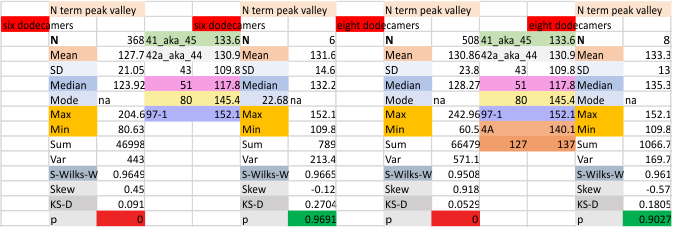
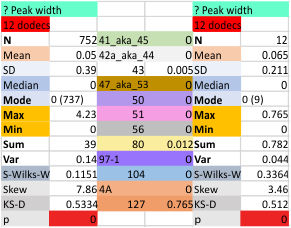
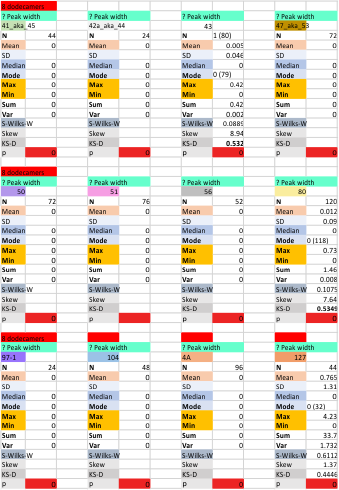
It has come up in many discussions how the N term peak in surfactant protein D may have a dark center, and this is particularly evident when one looks at the AFM images of multimers of more than just a few trimers. Some multimers actually have a deep empty center. Only in a few dodecamers is there a sub peak in the large, prominent peak for the N term junction. I looked for that indication in all the plots of the hexamers so far and it shows up very infrequently, and the data below just sort of negate that inner subpeak as non existent. It may be highly infrequent in the dodecamers, but it is not that infrequent in multimers, and thus anytime it shows up in a dodecamer becomes important in considering just how the N term domains fit together in the multimers, and if in fact they can fit together in more than one way. So the data below is pretty uninteresting, but the image and the plot (image is 2D fast fourier tranform in gwyddion. The peak detection is made in Octave using ipeak.m M80 as the settings. Coloration of the peaks in the plot are a choice that best fits the mean number of peaks per hexamer — which was determined to be 15 (see previous data). Top image is the AFM micrograph, image filters and signal processing for plot peaks. 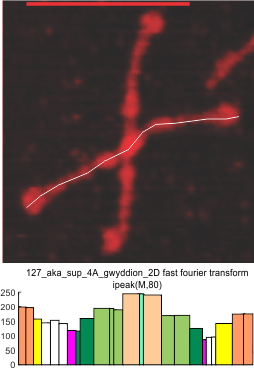
Mid N term peak width (N=752, trimers plotted)(N=12 dodecamers (two hexamers, four trimers). Data below also shows each individual dodecamer…. and as mentioned, most don’t show a peak in the middle of the N term peak.
Category Archives: Methods to assess TEM and AFM images
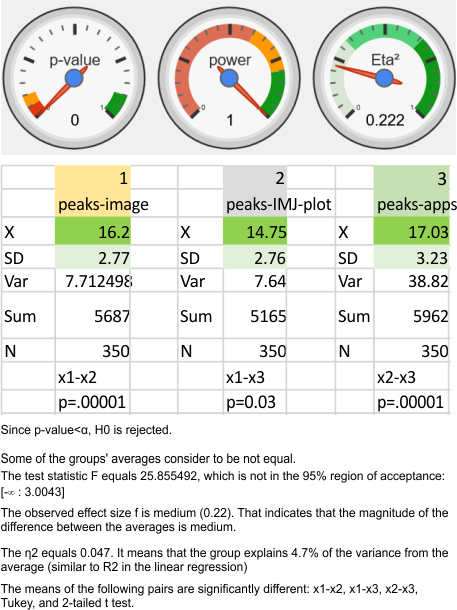
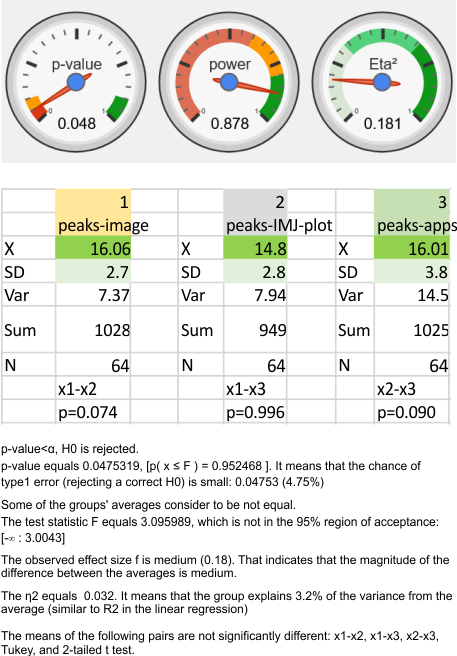
ANOVA: peak counts using images vs apps
Nice online ANOVA caltulator (i like the colors and graphics especially, even though I have not ever tried to grasp statists). To me it looks like there are significant differences between what “I” see initially on the image, what “I” count as peaks on the plots generated from the images in ImageJ, and what the various signal processing apps that detect as peaks on those same excel plots. Top image. These data are for all 14 dodecamers, the most current set of peak counting data so far.
When I separate out JUST MY peak counts of the images (before and/or after image processing filters) and then just MY counts on the initial plot images in ImageJ, and then my recounts of the peak separation when adding up the sub-peaks into the preset 15 peaks (found previously by an average of hundreds of plots)…. I personally am pretty consistent in how i see the peak number in each image. Bottom image.
“peak” or not to “peak”
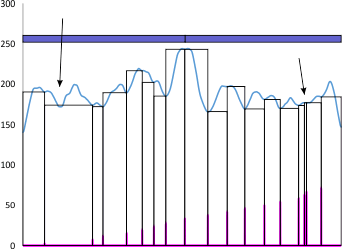 This is an example of why i get frustrated with peak detection apps…. vertical axis is grayscake 0-255, x axis not numbered is nm (which I have to calculate against a bar marker on the original micrograph) and is not really relevant here.
This is an example of why i get frustrated with peak detection apps…. vertical axis is grayscake 0-255, x axis not numbered is nm (which I have to calculate against a bar marker on the original micrograph) and is not really relevant here.
Peaks that are found are clearly marked at the point of valleys on each side, by the program (it is an excel program called PeakValleyDetectionTemplate.xls) and what this smooth function (smooth 11) thinks is a valley is highlighted in pink…. so i didn’t miss anything…. or add anything.
My draw program has a “snap too” function that snaps to the valley lines detected so I don’t even make the judgements in identifying those vertical valley indicator lines there so this program measures width between peaks with the lines (which I colored pink) and are easy to follow. BUT…
My ADDED arrow on the left points to a peak that I certainly would have called a peak that was not detected by this app, my added arrow on right points to a peak that I certainly would NOT have called a peak which this app thought was a peak (I could not even find a drop in grayscale of one single pixel).
Just out of wanting to know the facts in this study of SP-D, and trying to help determine the structure of the common multimer of SP-D (the dodecamer), I dont change those chosen valleys from the apps, I just report the results whether I agree with them or not. But sometimes these apps “think” (lol) too hard about lag, threshold, smooth, incidence, width, deviation, and influence etc…. and gloss over the obvious, not able to consider chance, inherent variability, possible radial and bilateral symmetry etc……..therefore at this point they are really not as good (in the method that I am using them) as human judgement (mainly mine ha ha ha) in my humble opinion. I also accept that this is a simple molecule, bilateral, with maybe 11-17 peaks routinely found. So its not a massive chaotic mess, but sometimes they just dont work.
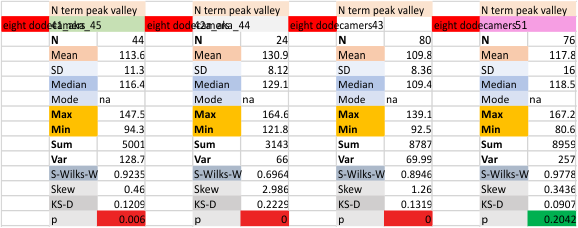
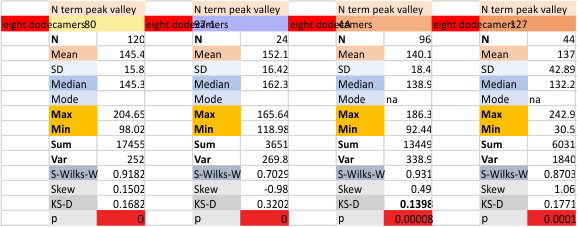
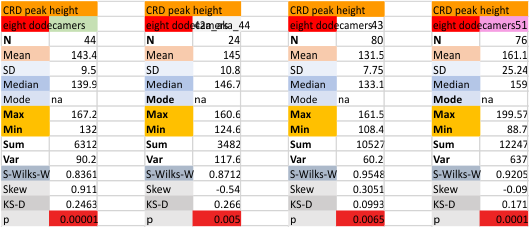
Eight dodecamers: SP-D – CRD peak height and valley
These data are the pretty final. The next dodecamers will be added as individuals only, not as the sum of the long list of plots (e.g. 508 trimer plots) but using only an N of a dodecamer (which seems to me to produce the best data. None of these data have had the width measurements standardized to a trimer length in nm (which will be done last). I guess it is possible to standardize the grayscale values as well.




Eight dodecamers: SP-D – peak 6 height and valley




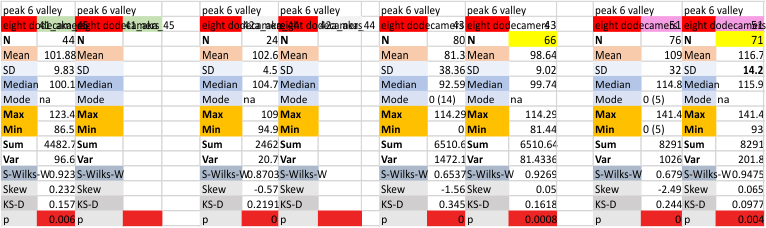

Eight dodecamers: SP-D – peak 5 height and valley






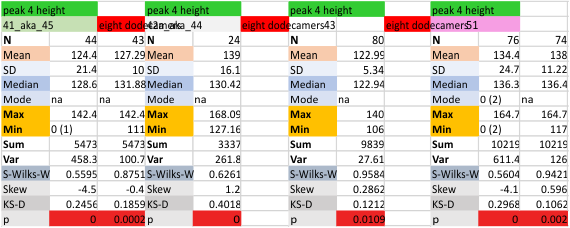
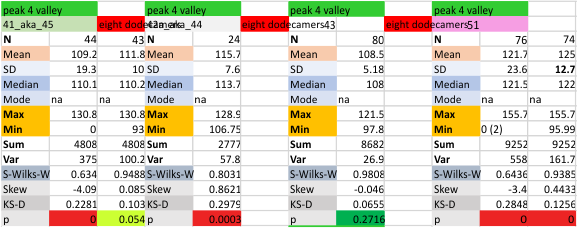
Eight dodecamers: SP-D – peak 4 height and valley
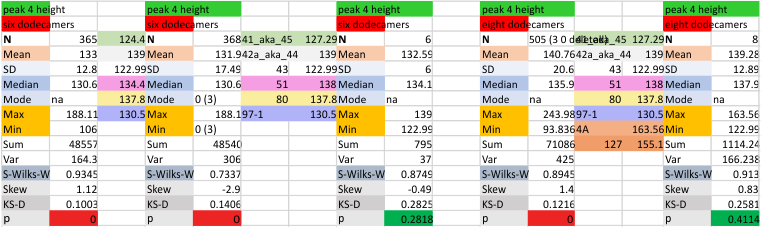



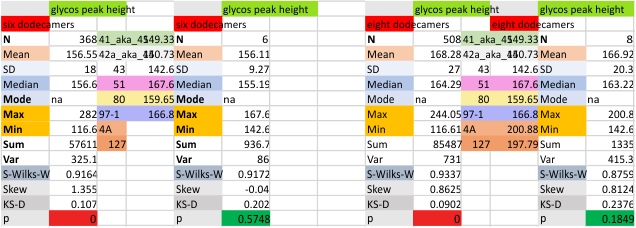
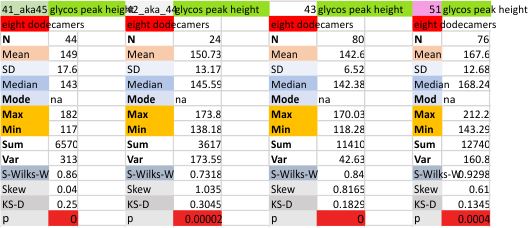
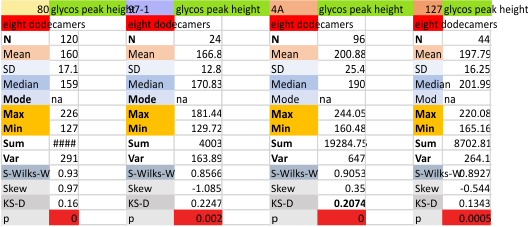
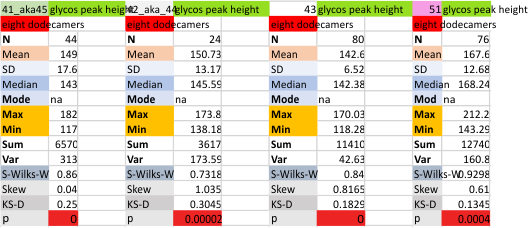
Eight dodecamers: SP-D – glycosylation peak height and valley
Same MO.
peak height
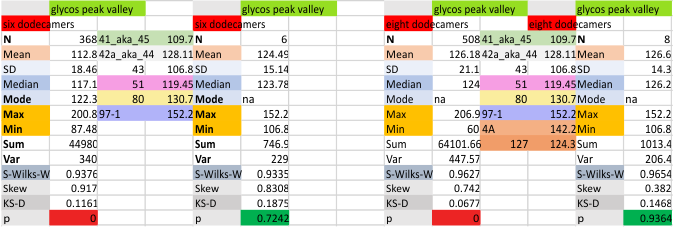
peak valley

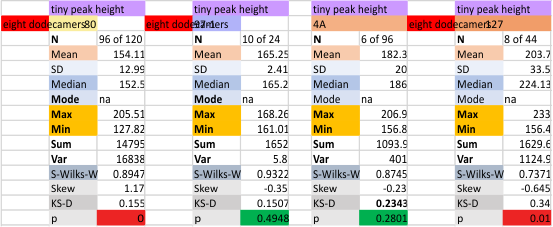
Eight dodecamers: SP-D – tiny peak height and valley
same mo.


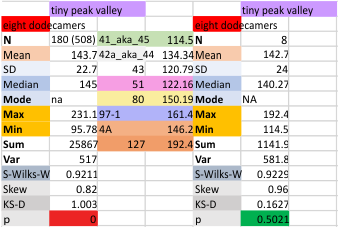


Eight dodecamers: SP-D – N termini junction peak height and valley
Peak height (grayscale values) for all plots of trimers from 8 dodecamers of SP-D. Mean peak height for the N term peak is something around 233nm +/18nm.
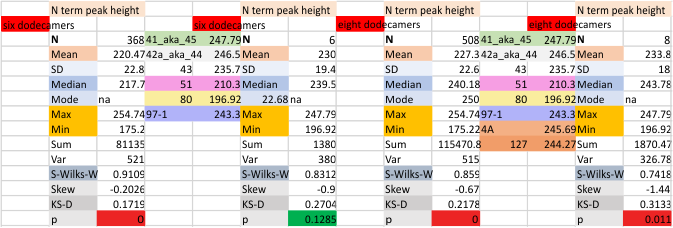
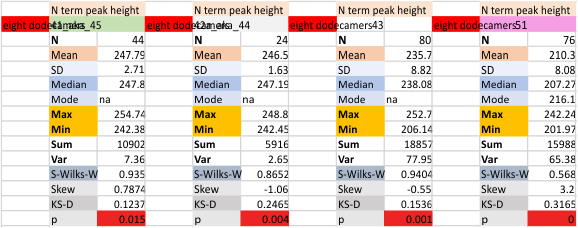
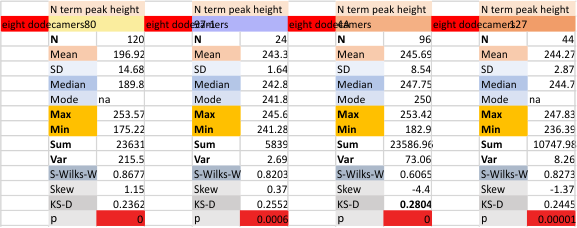
Lower images are peak valley (grayscale 0-255, values plotted in ImageJ)