The graphics below are visual aids that I prepared for myself, just to help me visualize the value of image processing -with and without- subsequent signal processing of the grayscale (LUT) plots for peak detection. The goal is to determine what signal processing of plots offers in terms of determining structure within the images (molecules).
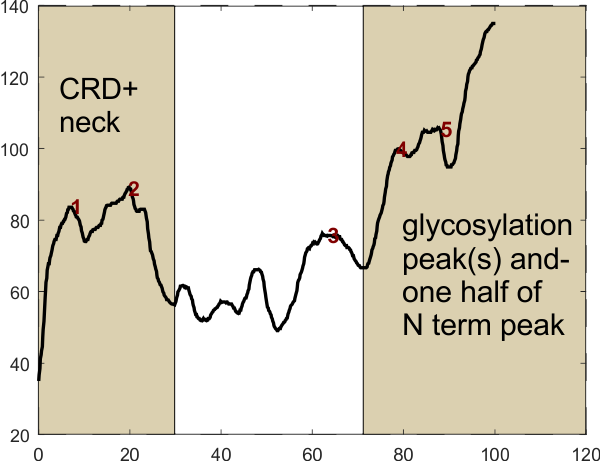
The graphic to the left: A crop of the same image, saved from three different published figures, is from a set of about 100 images of surfactant protein D (SP-D) I have used in all the previous posts about SP-D. This particular trimer a SP-D  dodecamer I named 97, and it has been shown elsewhere on this blog, on numerous occasions, and individuals have been credited for it in previous posts.
dodecamer I named 97, and it has been shown elsewhere on this blog, on numerous occasions, and individuals have been credited for it in previous posts.
Summary of the image to the left: Three screen shots were made of one dodecamer (this is just a portion of that image), from published articles, each of a different resolution (i.e. digital resolution). One can see the gradation of pixelation of these cropped images (just the carbohydrate recognition domain of a trimer) best resolution at the top, worst at the bottom. The three images were resampled to 8in wide, 300ppi, bit depth 32, but the graphic to the left shows that the original pixellation is present in each even after resampling. The least pixelated image is 97-1, then 97-2, and particularly 97-3, is pixelated. These same three images were then image-processed using two filters, both applied in Gwyddion and exported as tif files. The filters were, 97-1 – gaussian blur 5px, limit range 130-255; 97-2 gaussian blur 10px, limit range 130-255; and 97-3 gaussian blur 15px, limit range 130-255. Greater degrees of gaussian blur were used to reduce the pixellation in the images 97-2 and 97-3. The resulting images were plotting using a 1px segmented line through the center of the trimer in ImageJ to determine brightness (grayscale, 0-255) and plots were exported to excel.
In addition, using ImageJ, a duplicate of each of the three processed images was also resampled, one set at 5000px and the other set at 50px. The benefit from a second resampling to 5000px wide can be seen in the graphic below, but the 50px images were basically useless, but amazingly, some signal processing programs could find peaks in the appropriate places.
As a summary of image-processing, sets of the three images (97-1, 2 and 3) were treated as follows: 1) the originals were resampled at 300ppi; 2) resampled images were subjected to gaussian blur – limit range filters, 3) duplicates of the second set were resampled in ImageJ, at a5000px or at 50px to become the third and fourth sets. The plot below reflects the mode of the peaks found in each plot, that is, a count of the number of peaks derived from each image as it is subjected to various signal processing algorithms. Overall, something between 8 and 10 peaks are present in plots of most most images, whether processed just with image processing, or both image and signal processing algorithms.
The most pleasing data come from the column (far right), and surprisingly it was from 97-3 the most pixelated original image, which was compensated for by a 15px gaussian blur. It may however be an undercount of the actual number of peaks along a trimer of SP-D. Very likely the mode, which is 9 peaks is most reflective of this trimer, and others I have seen.
 The ImageJ plots were subjected to 29 different algorithms to determine peak number per trimer. That list is in a post HERE and listed again at the bottom of this blog. Excel was used to create a graphic with the number of peaks found in the 299 resulting plots. It has been color coded according to the number of peaks that each signal processing program produced for each of the 3 images and their 3 variations (remember the 50px set was discarded). Color coding: blues and greens represent the smaller number of peaks along a trimer, and reds and browns represent the higher number (sometimes “off the charts” depending on the settings on the Octave and xlsx template functions) of peaks that the algorithms produced. It doesnt take much looking to see that the greatest gaussian blur and 5000px resampling make for the best signal processed peak results (columns 2, 6,7 and 8,9 regardless of algorithms used for signal processing (bottom image). On the vertical legend on the right, bold numbers are counts of peak with numbers corresponding to the most right row, e.g. 2 image-signal processed plots came up with 2 peaks, etc, or you can count them yourself. My subjective counts, pink columns most left, lag threshold influence settings 8 tan collumns, ImageJ find peaks, brown columns, light blue, PeakValleyDetection xlsx, PeakDetection xlsx medium blue, darker blue was Octave, findpeaksplot.m, and most 2 right columns, Octave AutoFindPeaksPlot.m. values for the two Octave .m sets are listed in below, as are settings for the xlsx peak finding templates. LTI settings given as well.
The ImageJ plots were subjected to 29 different algorithms to determine peak number per trimer. That list is in a post HERE and listed again at the bottom of this blog. Excel was used to create a graphic with the number of peaks found in the 299 resulting plots. It has been color coded according to the number of peaks that each signal processing program produced for each of the 3 images and their 3 variations (remember the 50px set was discarded). Color coding: blues and greens represent the smaller number of peaks along a trimer, and reds and browns represent the higher number (sometimes “off the charts” depending on the settings on the Octave and xlsx template functions) of peaks that the algorithms produced. It doesnt take much looking to see that the greatest gaussian blur and 5000px resampling make for the best signal processed peak results (columns 2, 6,7 and 8,9 regardless of algorithms used for signal processing (bottom image). On the vertical legend on the right, bold numbers are counts of peak with numbers corresponding to the most right row, e.g. 2 image-signal processed plots came up with 2 peaks, etc, or you can count them yourself. My subjective counts, pink columns most left, lag threshold influence settings 8 tan collumns, ImageJ find peaks, brown columns, light blue, PeakValleyDetection xlsx, PeakDetection xlsx medium blue, darker blue was Octave, findpeaksplot.m, and most 2 right columns, Octave AutoFindPeaksPlot.m. values for the two Octave .m sets are listed in below, as are settings for the xlsx peak finding templates. LTI settings given as well.

list of image/signal processing. beginning with top left on graph above, list of all the signal processing used on the 10 images. RED indicates which ones I thought were best.
my count of peak number from the image
my count of peak number from ImageJ plot
LagThresholdInfluence 1, 0.5 0.025
LagThresholdInfluence 1, 0.7 0.05
LagThresholdInfluence 1, 0.1 0.01
LagThresholdInfluence 5 0.5 0.5
LagThresholdInfluence 5 0.5 0.05
LagThresholdInfluence 10, 0.1 1
LagThresholdInfluence 10 0.5 0.5
LagThresholdInfluence 10 0.5 1
ImageJ find maxima 0.5
ImageJ find maxima 1
ImageJ find maxima 2
PeakValleyDetection xlsx smooth width 1
PeakValleyDetection xlsx smooth width 3
PeakValleyDetection xlsx smooth width 5
PeakValleyDetection xlsx smooth width 7
PeakValleyDetection xlsx smooth width 9
PeakValleyDetection xlsx smooth width 11
PeakDetection xlsx amp t 0.6 slope t 2.5- M6=-4,N6=-3
PeakDetection xlsx amp t 1 slope t 1 -M6=-3,N6=-4:
PeakDetection xlsx amp t 0.6 slope t 2.5 -M6=-3,N6=-4
findpeaksplot x,y,0.0001,80,9,16,3
findpeaksplot x,y,0.0003,0,11,21,4
findpeaksplot x,y,0.0008,40,9,16,3
findpeaksplot x,y,0.0003,0,11,35,4
findpeaksplot x,y,0.005,5,7,7,3
autofindpeaksplot.m x,y,0.00041228,63.5713,16,16,3
autofindpeaksplot.m x,y,0.00039524,74.8105,17,17,3
Using just the results for the algorithms above in “red”
9 peaks in a trimer of SP-D (n-1 trimer…LOL) but it is a start.
N 11
Sum 99
Mean 9+/-1.3
Var 1.8