The length of a trimer was determined from the center of the N termini junction peak to the edge of the carbohydrate domain (since this is a lumpy molecule…. the most central route for the line (plot) through the CRD was used. Many examples of the type of line are given in previous posts.
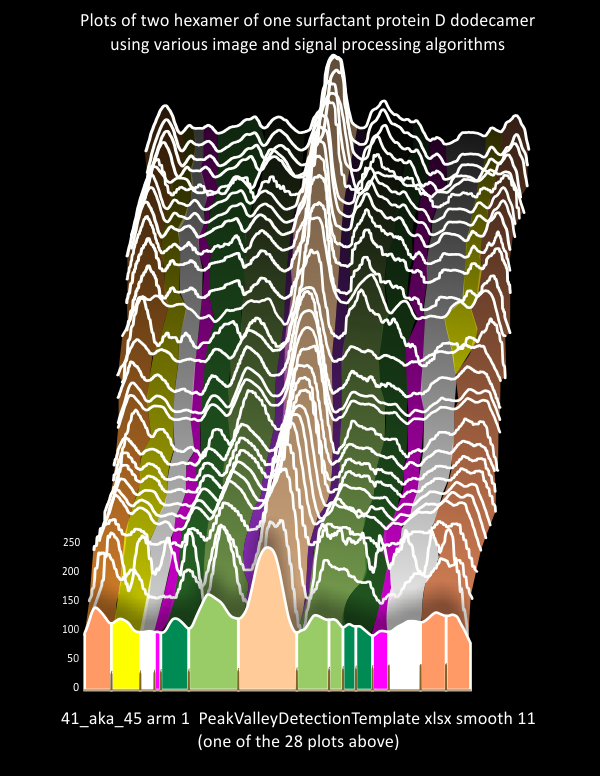
Applications were AS BEFORE- No processing, gaussian blur (5 or 10px) and gaussian blur with limitrange (100 (or above)-255), and each is then subjected to all of the following signal processing applications for peak detection: Lag 5, Threshold 1, Influence 0.05 (batch process), Scipy (Prominence 2, Distance 30, Width 5, Threshold -, Height -), Octave, autofindpeaksplotx,y and iPeaksM80, and excel template PVDTxlsx smooth 11. This means that there are two hexamers (four trimers) each with no processing, some processing, and each of the latter subjected to 5 different signal processing routines. Some select other processing can be included.
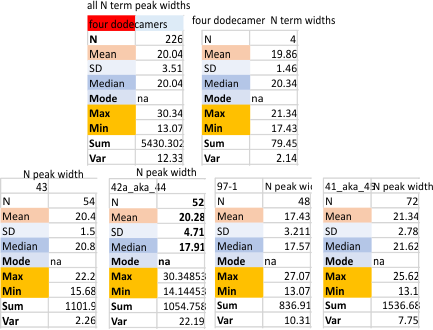
Trimer widths in nm, as all lumped values, individual values, and as a single group of four.

The number of peaks per trimer is calculated with all independent measures, as molecule measures (that would be each trimer of four individual SP-D images). The N term peak is calculated in full, WITH each N term peak that is not divided into two peaks. So adding up the peak number — keep in mind that N is counted twice if it is a single large peak.
 Previously, using dozens of image and signal processing programs for literally hundreds of plots, of a single SP-D image (41_aka_45), the number of peaks per trimer was 8. Check out the post here. It is very encouraging to have a selected set of image and signal processing programs provide almost identical results to that original single molecule dataset. That means to me that the gaussian blur and limit range imaging filters can be used somewhat confidently to provide easier counting of peaks along an arm of a hexamer (or trimer) of SP-D.
Previously, using dozens of image and signal processing programs for literally hundreds of plots, of a single SP-D image (41_aka_45), the number of peaks per trimer was 8. Check out the post here. It is very encouraging to have a selected set of image and signal processing programs provide almost identical results to that original single molecule dataset. That means to me that the gaussian blur and limit range imaging filters can be used somewhat confidently to provide easier counting of peaks along an arm of a hexamer (or trimer) of SP-D.
Just analyzing the left hand side of each of the four images, the trimer length in nm is different (as relates most likely to preparation artifact, in stretching or folding of the arms.
 just the righ hand side of the image (the second trimer in the hexamers to be traced are as follows.
just the righ hand side of the image (the second trimer in the hexamers to be traced are as follows.

 There are so many ways to sum these arms up i just decided to do them separately as 16 trimers comprising 4 dodecamers. It makes little difference that i can detect and a nice conservative number of 145 nm as the usual hexamer length, and 73 for the usual trimer length (not exact yes… ). but counting more molecules might be more efficacious than deliberating on just four.
There are so many ways to sum these arms up i just decided to do them separately as 16 trimers comprising 4 dodecamers. It makes little difference that i can detect and a nice conservative number of 145 nm as the usual hexamer length, and 73 for the usual trimer length (not exact yes… ). but counting more molecules might be more efficacious than deliberating on just four.

Two conclusions. 1) Image processing is helpful, signal processing to count peaks, not so much. The plots smoothed with the gaussian blur and enhanced with the limit range function are easy enough to manually count peaks, and the peaks counted manually are guided by ones knowledge which the current algorighms are not (as in not recognizing symmetry, and not permitting small peaks to follow big ones. etc). When a few more molecules are counted and added to the list then perhaps I will find someone who knows how to “train” peak counting algorighms. LOL.
2) The number of peaks per hexamer is likely to be between 13 and 15. THis is much greater than that proposed by Arroyo et al, who found 5.